DL Land cover#
Land cover classification at 1-meter spatial resolution using aerial imagery and deep learning
Developed by Dakota Hester
Land cover classification is an important task in remote sensing: land cover maps are integral to monitoring the interaction between humans and the environment, as well as monitoring changes in natural resources. Land cover maps are typically created at medium spatial resolutions using remote sensing data from instruments aboard satellites (such as Landsat and Sentinel-2) that is processed by pixel-based machine learning algorithms. However, at high resolutions (<5 meters), the effectiveness of pixel-based approaches to classification of remote sensing imagery tends to decrease due to increased intra-class variance and the prevalence of noise in the data. Deep learning approaches, on the other hand, use both spectral and spatial information when processing remote sensing data, alleviating some of the negative effects of aforementioned increased intra-class variance. This purpose of this tutorial is to provide a basic introduction for applying deep learning methods to remote sensing data. In particular, we will be training a modified U-Net semantic segmentation model to create an end-to-end approach to land cover classification.
Data sources#
In order to develop a deep learning model, we need a large source of labelled imagery for supervised training. The Chesapeake Bay land cover dataset is a 6 class 1-meter spatial resolution land cover dataset over the Chesapeake Bay watershed on the east coast of the United States. The labels in the target data correspond to the following land cover classes:
1 = water
2 = tree canopy / forest
3 = low vegetation / field
4 = barren land
5 = impervious (other)
6 = impervious (road)
15 = no data (none in this dataset).
For our source imagery, we will use USDA NAIP 4-band (red, green, blue, NIR) aerial imagery resampled to 1-meter ground sampling distance (GSD). The Chesapeake LC dataset was created using NAIP, Landsat 8, NLCD, building footprint data, and road maps which is included in the full dataset. For simplicity’s sake, we will only use the NAIP data. Follow this link for more information regarding the Chesapeake Bay LULC dataset. Below is the extent of the full LULC dataset.
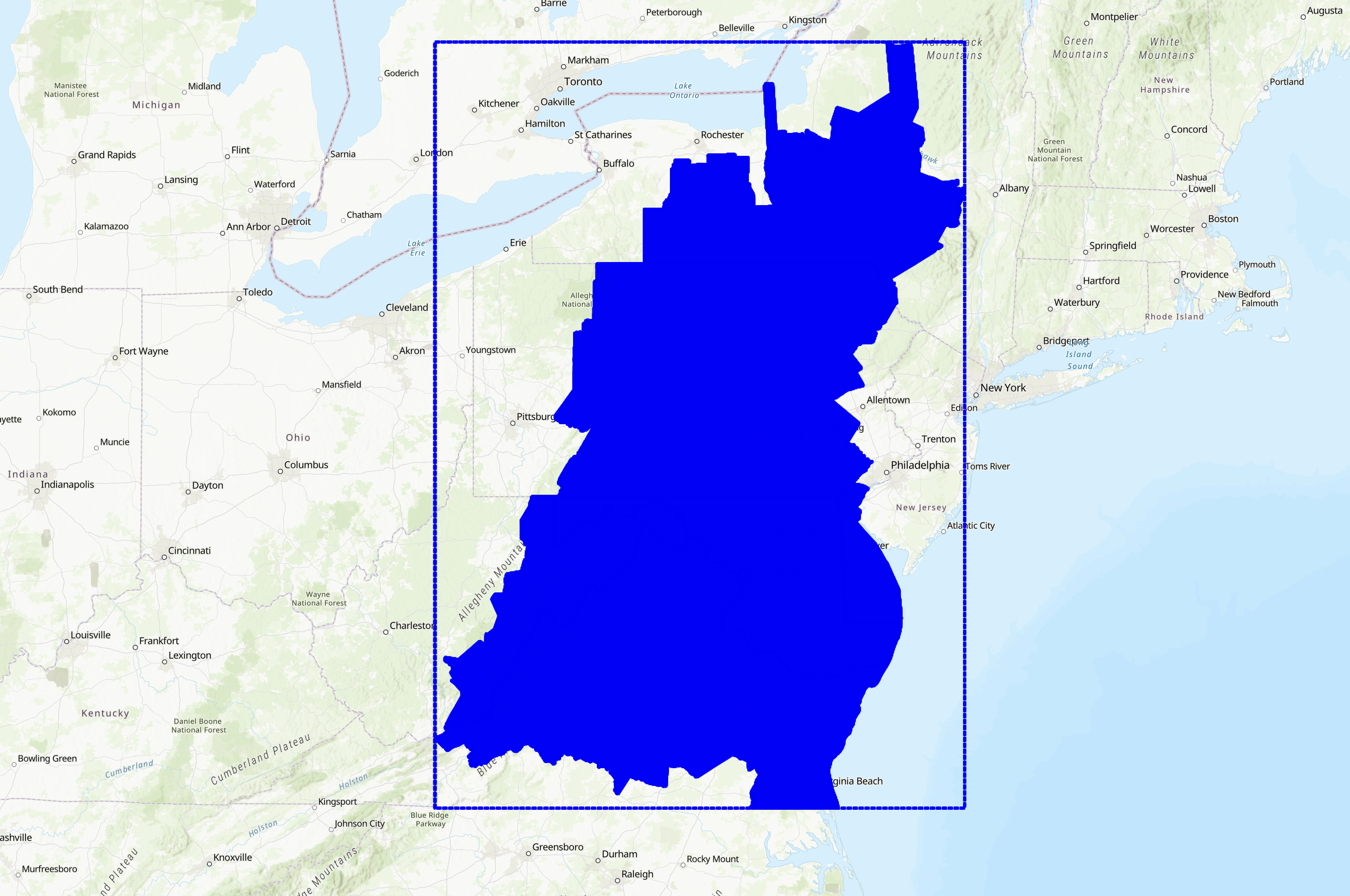
We will only be using a small subset of the dataset for this example. Specifically, the dataset consists of 10 NAIP scenes from the east coast of Virginia and their corresponding land cover annotations. Each scene has been sampled into a grid of 224x224 patches. The data is stored in the ./data directory in this repository.
Loading data#
In order to load data from rasters into python, we need to use the rasterio module. Below is an example of how to open and visualize a file using rasterio.
Finding files#
Before we can load files, we need to know where they are at. In this case, there is some NAIP data that has aleady been sampled stored in ./data with the following directory structure:
| unet_data/
|| NAIP_PATCH_ID/
||| input/
|||| 00000.tif (sample from corresponding patch)
|||| 00001.tif
|||| 00002.tif
|||| ...
||| target/
|||| 00000.tif (sampl from corresponding patch's ground truth data)
|||| 00001.tif
|||| 00002.tif
|||| ...
Knowing this, we can write a function that aggregates the NAIP data and their corresponding ground truth labels into a list of 2-tuples.
import os
def get_list_of_files(data_path: str=r'\dataset\raster\unet_data') -> list[tuple[str, str]]:
'''Returns a list of tuples of the form (path_to_input_sample, path_to_label)
Parameters:
data_path (str): path to the root of the data directory
Returns:
list[tuple[str, str]]: List of file paths with corresponding ground truth labels
'''
# get list of patch ids. list comprehension pretty much says "look at the
# items in the data_path directory and if they are directories, add them to
# the list"
file_paths = []
patch_ids = [sub_dir for sub_dir in os.listdir(data_path) if os.path.isdir(os.path.join(data_path, sub_dir))]
for patch in patch_ids:
# get all subsamples of each patch
subsamples = os.listdir(os.path.join(data_path, patch, 'input'))
# add subsamples to file_path list
file_paths.extend(
(
os.path.join(data_path, patch, 'input', subsample),
os.path.join(data_path, patch, 'target', subsample)
) for subsample in subsamples
)
# check to make sure files exist
for file_path in file_paths:
if not os.path.isfile(file_path[0]): # if source file doesn't exist
raise FileNotFoundError(f'Input file {file_path[0]} not found')
if not os.path.isfile(file_path[1]): # if label file doesn't exist
raise FileNotFoundError(f'Label file {file_path[1]} not found')
return file_paths
file_paths = get_list_of_files(r'D:\jupyterbooks\gcersat\dataset\raster\unet_data')
print(f'Found {len(file_paths)} files') # always a good idea to print out the number of files found
print(file_paths[0]) # take a look at the first file path input/target 2-tupledataset/raster/unet_data
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_40384\1356497114.py in <module>
1 import os
----> 2 def get_list_of_files(data_path: str=r'\dataset\raster\unet_data') -> list[tuple[str, str]]:
3 '''Returns a list of tuples of the form (path_to_input_sample, path_to_label)
4
5 Parameters:
TypeError: 'type' object is not subscriptable
Now, lets look through our files and visualize the data to make sure that we have the right data and that we are loading it into Python correctly.
import rasterio
import numpy as np
from rasterio.plot import show
src_file = file_paths[0][0] # first sample, only the input data
with rasterio.open(src_file) as src:
meta = src.meta # grab geo metadata
data = src.read() # grab raster data (as numpy array)
red_band = src.read(1) # only grab red band (as numpy array)
print('raster metadata:', meta)
print('raster shape:', data.shape)
print('red band raster shape:', red_band.shape)
data_rgb = data[:3] # create RGB image
show(data_rgb, transform=meta['transform'], vmin=0, vmax=255, title='RGB')
data_cir = data[[3, 0, 1], :, :] # grab only the G R NIR bands
show(data_cir, transform=meta['transform'], vmin=0, vmax=255, title='CIR')
target_file = file_paths[0][1] # first sample, only the target data
with rasterio.open(target_file) as src:
target_meta = src.meta # grab geo metadata
target = src.read() # grab raster data (as numpy array)
show(target, transform=target_meta['transform'], vmin=1, vmax=7, title='Target')
raster metadata: {'driver': 'GTiff', 'dtype': 'uint8', 'nodata': None, 'width': 224, 'height': 224, 'count': 4, 'crs': CRS.from_epsg(26918), 'transform': Affine(1.0, 0.0, 413351.0,
0.0, -1.0, 4055221.0)}
raster shape: (4, 224, 224)
red band raster shape: (224, 224)

<Axes: title={'center': 'Target'}>
In order to make our life easier down the line, let’s go ahead and create a few helper functions for working with raster data. First, let’s create a function that prints the shape (dimensionality) of an array, along with other important properties.
def print_array_info(array):
print('array shape:', array.shape)
print('array dtype:', array.dtype)
print('array range:', array.min(), array.max())
print_array_info(data)
print_array_info(target)
array shape: (4, 224, 224)
array dtype: uint8
array range: 27 165
array shape: (1, 224, 224)
array dtype: uint8
array range: 1 1
Now, let’s create functions for vizualizing raster and label data easily.
import matplotlib.pyplot as plt
def visualize_raster(raster, title=None):
rgb = raster[:3] # create RGB image
cir = raster[[3, 0, 1], :, :] # grab only the G R NIR bands
rgb = rgb.transpose(1, 2, 0) # convert from (bands, rows, cols) to (rows, cols, bands)
cir = cir.transpose(1, 2, 0)
# create plt figure
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
# plot RGB image
ax[0].imshow(rgb, vmin=0, vmax=255)
ax[0].set_title('RGB')
ax[0].axis('off')
# plot CIR image
ax[1].imshow(cir, vmin=0, vmax=255)
ax[1].set_title('CIR')
ax[1].axis('off')
if title is not None:
fig.suptitle(title)
fig.tight_layout() # formatting
plt.show()
visualize_raster(data, 'test raster')

When creating maps from land cover data, often it is convenient to create a color profile that corresponds to the legend elements instead of using a standard color map. As a refresher - here are the land cover classes we are working with:
1 = water
2 = tree canopy / forest
3 = low vegetation / field
4 = barren land
5 = impervious (other)
6 = impervious (road)
15 = no data.
Thankfully, matplotlib provides an easy interface for creating a custom color map using the ListedColorMap class, and an interface for customizing legend entries with the corresponding colors using the Patch class.
from matplotlib.colors import ListedColormap
from matplotlib.patches import Patch
land_cover_colors = [
'blue', # 1 - water
'darkgreen', # 2 - tree canopy/forest
'lightgreen', # 3 - low vegetation/field
'yellow', # 4 - barren land
'darkgray', # 5 - impervious (other)
'lightgray', # 6 - impervious (road)
] # no nodata samples in our dataset, so no need to add a nodata color
land_cover_labels = [
'Water',
'Tree Canopy/Forest',
'Low Vegetation/Field',
'Barren Land',
'Impervious (Other)',
'Impervious (Road)',
]
land_cover_cmap = ListedColormap(land_cover_colors, name='land-cover') # create color map object
land_cover_legend = [
Patch(facecolor=land_cover_colors[0], label=land_cover_labels[0]),
Patch(facecolor=land_cover_colors[1], label=land_cover_labels[1]),
Patch(facecolor=land_cover_colors[2], label=land_cover_labels[2]),
Patch(facecolor=land_cover_colors[3], label=land_cover_labels[3]),
Patch(facecolor=land_cover_colors[4], label=land_cover_labels[4]),
Patch(facecolor=land_cover_colors[5], label=land_cover_labels[5]),
]
def visualize_target(target, title=None):
if target.ndim == 3: target = target.squeeze(0) # remove extra dimension if necessary
fig, ax = plt.subplots(1, 1, figsize=(5, 5))
ax.imshow(target, cmap=land_cover_cmap, vmin=0, vmax=6) # plot target image
ax.axis('off')
fig.legend(handles=land_cover_legend, loc='lower center', bbox_to_anchor=(0.5, -.1), ncol=3) # add legend
if title is not None:
fig.suptitle(title)
fig.tight_layout()
plt.show()
target = target - 1# subtract 1 from all values to make the range 0-6 instead of 1-7
visualize_target(target, 'Test target')
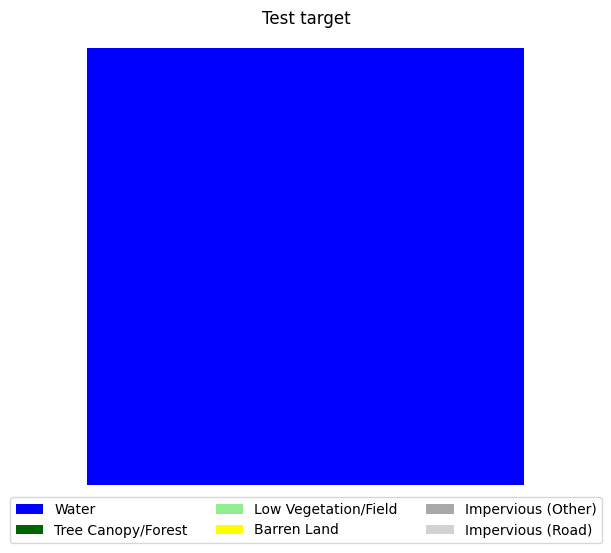
Finally, let’s create one more function that plots the class distribution of a dataset.
def plot_class_distributuion(y):
class_dist = np.unique(y, return_counts=True)[1] # get counts of each class
class_dist = class_dist / class_dist.sum() # standardize to sum to 1
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
ax.bar(range(len(class_dist)), class_dist)
ax.set_xticks(range(len(class_dist)))
ax.set_xticklabels(land_cover_labels)
ax.set_ylabel('Number of Samples')
ax.set_title(f'Class Distribution: n_samples = {len(y)}')
fig.tight_layout()
plt.show()
return class_dist
# # load all target data
y = np.array([rasterio.open(target_file).read() for _, target_file in file_paths])
y = y - 1 # subtract 1 from all values to make the range 0-6 instead of 1-7
# plot class distribution
y_class_dist = plot_class_distributuion(y)
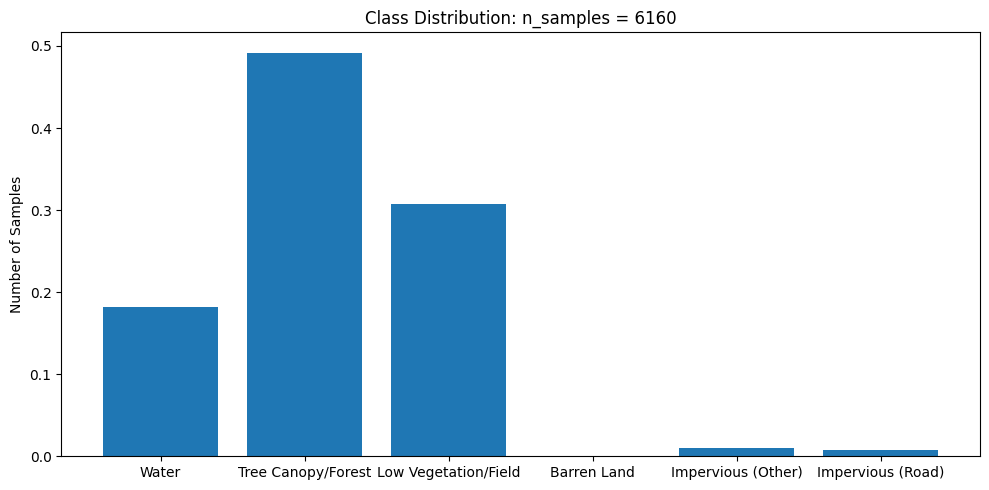
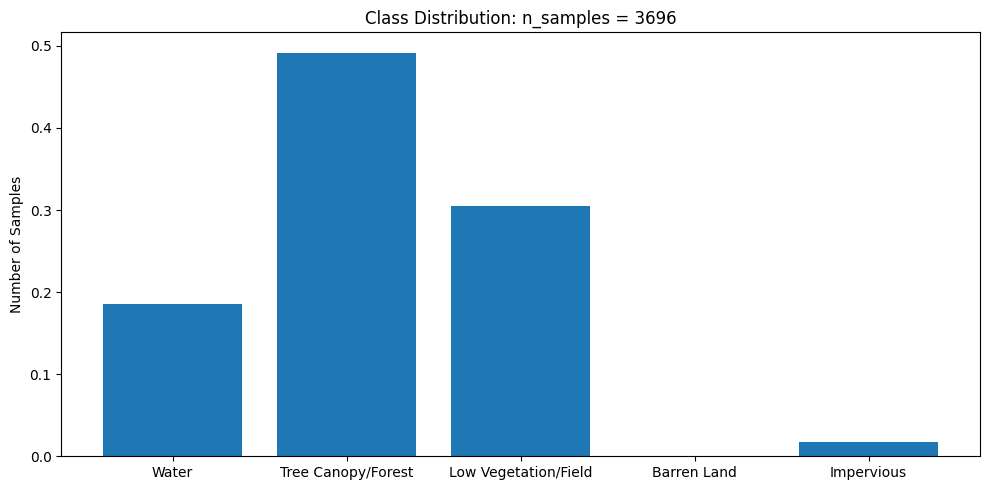
This dataset is very imbalanced. There are barely any barren land pixels in the labels, and water/forest/vegetation classes dominate the dataset. In order to tackle this, we will merge the impervious classes into one class and adjust the loss function to overemphasize underrepresented samples.
Merging impervious classes#
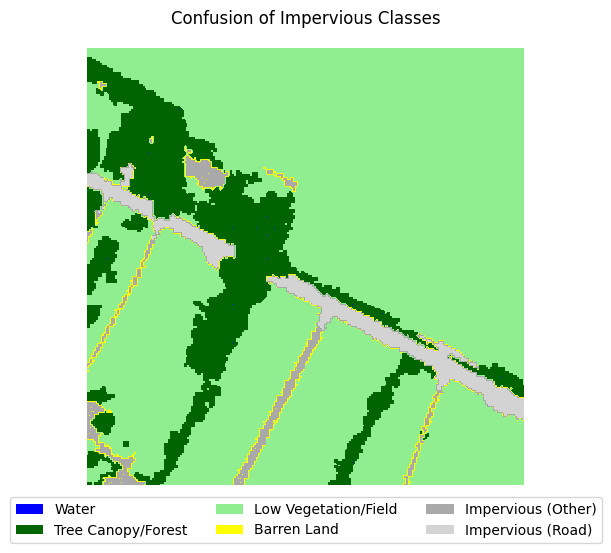
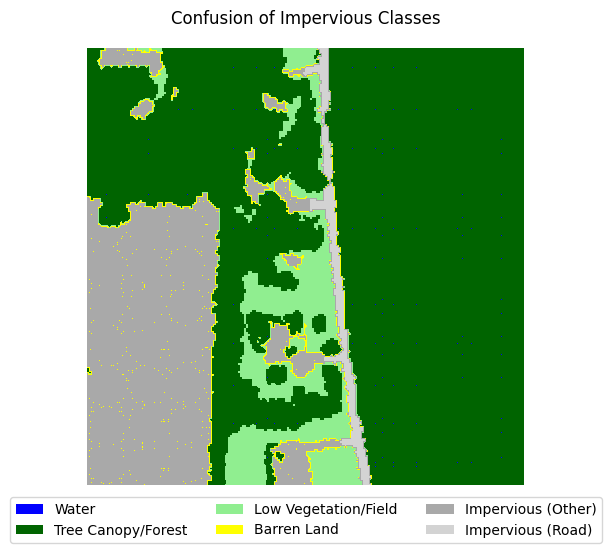
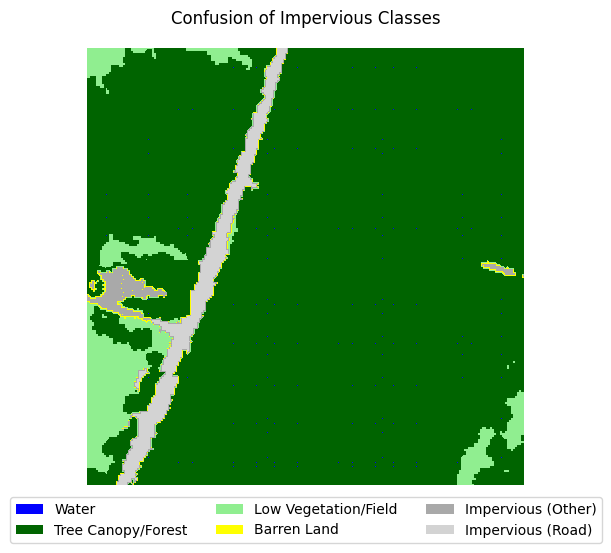
If you take a look at the samples in the dataset that contain impervious structures, you’ll notice quite a bit of misclassification between roads and other impervious structures. This dataset used an external road database to aid in the classification of impervious structures. However, because we are not working with such data, and the dataset’s annotations are spotty between the two classes, we can justify merging the two classes into a single “impervious” class
sample_idxs_with_impervious = [
idx for idx, sample in enumerate(y) if 4 in sample and 5 in sample
]
for i in range(5):
label_to_viz = y[sample_idxs_with_impervious[i]]
visualize_target(label_to_viz, title='Confusion of Impervious Classes')
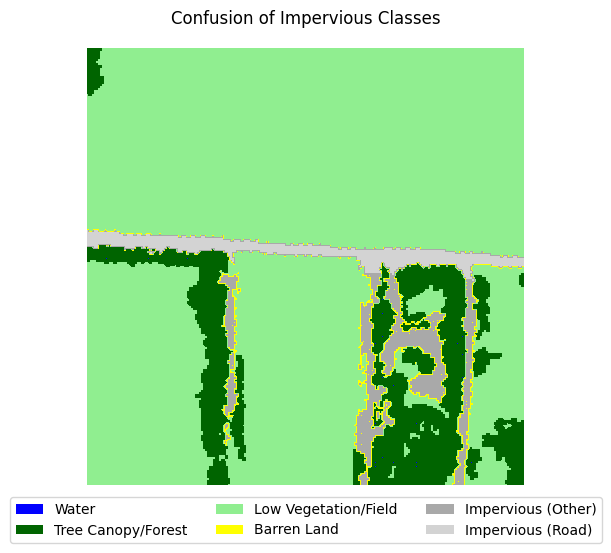
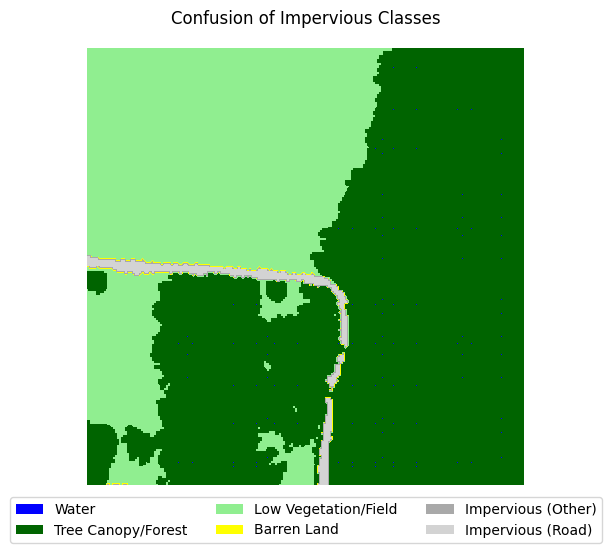
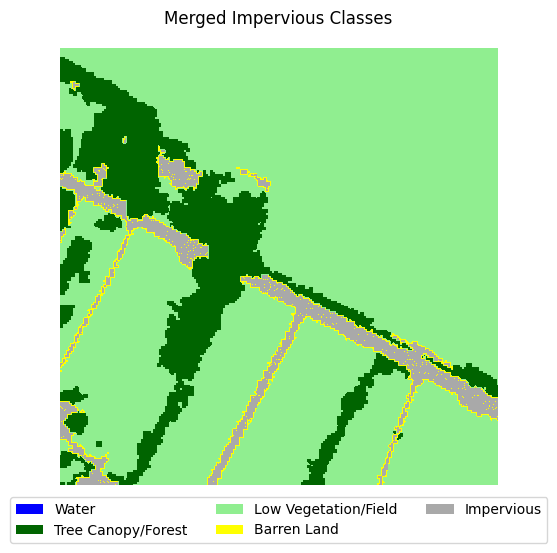
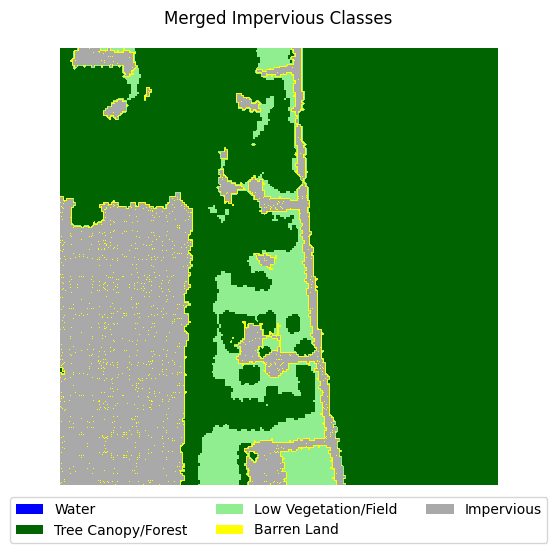
Let’s define a function that merges the two classes, then adjust the land cover legend to reflect those changes.
def merge_impervious_classes(label):
label[label == 5] = 4
return label
land_cover_labels.pop(5) # remove impervious (road) from labels
land_cover_labels[4] = 'Impervious' # rename impervious (other) to just impervious
land_cover_legend.pop(5) # remove impervious (road) from legend (for plotting)
land_cover_legend[4].set_label(land_cover_labels[4]) # rename impervious (other) to just impervious (for plotting)
for i in range(5):
label_to_viz = merge_impervious_classes(y[sample_idxs_with_impervious[i]])
visualize_target(label_to_viz, title='Merged Impervious Classes')
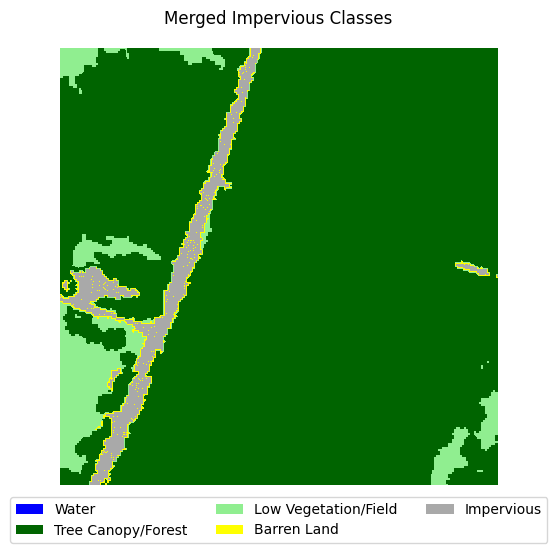

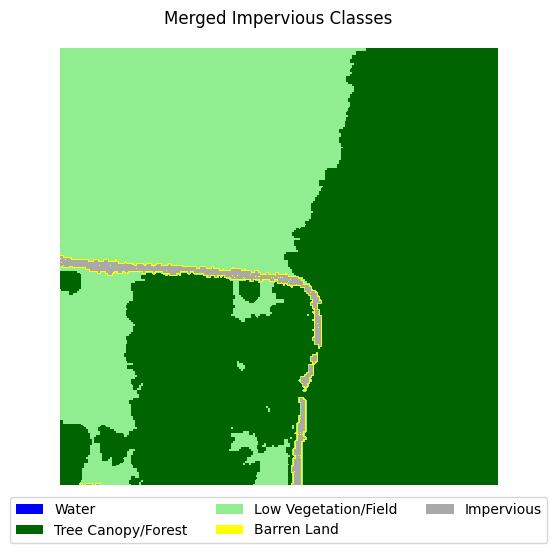
Creating train/test/val splits#
When training a deep learning model, we need at least 2 different dataset splits: a training split which consists of samples the models will train with, and a holdout set with samples that the model will not use during training. Additionally, it is also a good idea to create a validation set that is similar in size to the test split that will be used after each epoch is training is completed to determine how well the model can generalize to unseen data. If the loss calculated on the validation set is significantly greater than that of the training dataset, then our model is overfitting. Backpropogation is not performed on the validation or test splits meaning they have no impact on the parameters or performance of the model - these splits exist purely for evaluation purposes.
In this example, we are simply going to randomly choose samples to go in each split. Typically 20% of the dataset is placed in the test and validation splits respectively, whereas the remaining 60% is placed in the validation split.
import random
random.seed(1701) # set random seed for reproducibility
n_total_samples = len(file_paths)
n_test_samples = int(n_total_samples * 0.2) # 20% of data will be used for testing
n_val_samples = int(n_total_samples * 0.2) # 20% of data will be used for validation
n_train_samples = n_total_samples - n_test_samples - n_val_samples # the rest of the data will be used for training
print(f'Total samples: {n_total_samples}')
print(f'Train samples: {n_train_samples}')
print(f'Validation samples: {n_val_samples}')
print(f'Test samples: {n_test_samples}')
# shuffle the file paths (in-place operation)
random.shuffle(file_paths)
# split file paths into train, test, and validation sets
train_file_paths = file_paths[:n_train_samples]
val_file_paths = file_paths[n_train_samples:n_train_samples+n_val_samples]
test_file_paths = file_paths[n_train_samples+n_val_samples:]
Total samples: 6160
Train samples: 3696
Validation samples: 1232
Test samples: 1232
y_train = np.array([rasterio.open(file[1]).read() for file in train_file_paths]) - 1 # subtract 1 from all values to make the range 0-6 instead of 1-7
y_train = np.array([merge_impervious_classes(y) for y in y_train]) # merge impervious classes
class_dist = plot_class_distributuion(y_train) # look at class distribution
Creating a Dataset class#
In order to load data to train a neural network model in PyTorch, we need to create a custom class that tells PyTorch how to load each sample into memory, and what transformations need to be performed on each sample. If you’re unfamiliar with this practice, you may not immediately see the value in it compared to simply using a list of samples or numpy arrays. Indeed, it may seem like more unnecessary boiler-plate code, but there are several important reasons why creating a custom torch.utils.data.Dataset class has its advantages:
Subclassing
Datasetgives us near complete control on how data is loaded and passed to the model. For small, simple datasets it often more than enough to use anumpyarray to load samples for training. However, when working with large, complicated datasets, we often need to load samples directly from the disk on the fly and transform them to be suitable for training. Using the__getitem__method gives us near-unlimited options with regards to the type of data we need to load, how that data is stored (memory, disk, network, etc.), and any transforms/pre-processing that needs to be performed on the data.Using the
Datasetclass allows us to unlock the powerful features of object-oriented programming. We can store important information about the dataset - such as the distribution of classes, means, standard deviations, metadata, and more and access them easily, from both within theDatasetclass definition and the object itself. As such, your dataset can have all sorts of useful properties outside of just the data. In the following example, we can have the__getitem__method of ourDatasetclass return the metadata of the sample - allowing us to easily save rasters with geospatial information on-the-fly during inference - but we’ll save that for another day.
In the following example, we will subclass Dataset to create a new NAIP_Dataset class with functions specific to raster data. Notably, we will load rasters into memory as they are requested instead of loading the entire dataset into memory. Pay extra attention to the __getitem__ method in the following class definition.
import torch
from torch.utils.data import Dataset
# our custom NAIP_Dataset class will inherit from the Dataset class
class NAIP_Dataset(Dataset):
def __init__(self, files: list[tuple[str, str]], transform=None):
self.file_path_list = files
self.transform = transform # more on this later
self.class_dist = None # we will use this later
# min and max values of the NAIP imagery (per bands)
X = np.array([rasterio.open(file[0]).read() for file in self.file_path_list])
self.mins = X.min(axis=(0, 2, 3), keepdims=True).squeeze(0)
self.maxs = X.max(axis=(0, 2, 3), keepdims=True).squeeze(0)
self.range = self.maxs - self.mins
def __len__(self):
return len(self.file_path_list)
# __getitem__() is called when indexed in the form dataset[i]
# typically a __getitem__() method returns a single sample from the dataset
# in the form of a tuple: (X, y) where X is the data fed into
# the model and y is the ground truch label associated with the data.
def __getitem__(self, index) -> tuple[torch.Tensor, torch.Tensor, dict]:
file_path = self.file_path_list[index] # get file path to laod
# load raster data to memory
X = rasterio.open(file_path[0]).read()
y = rasterio.open(file_path[1]).read()
# convert to torch tensors
X = torch.from_numpy(X).type(torch.FloatTensor) # convert to float tensor
y = torch.from_numpy(y).type(torch.FloatTensor) # convert to float tensor
# standardize input data
X = np.subtract(X, self.mins) # subtract min
X = np.divide(X, self.range) # divide by range
# subtract 1 from labels so that classes are indexed from 0 to 6 (instead of 1 to 7)
y = y - 1
# merge impervious classes
y = merge_impervious_classes(y)
# image transformations (more on this later)
if self.transform:
X, y = self.transform(X, y)
return X, y
# NOTE: we can add additional methods to our custom dataset class to make our
# lives easier. For example, let's create a method that returns the class distribution
# of the dataset
def get_class_distribution(self, density: bool=True) -> np.array:
if self.class_dist is not None: return self.class_dist # return cached result if available
# load all labels into memory (as numpy array)
labels = np.array([rasterio.open(file_path[1]).read() for file_path in self.file_path_list])
# subtract 1 from labels so that classes are indexed from 0 to 6 (instead of 1 to 7)
labels = labels - 1
labels = merge_impervious_classes(labels) # merge impervious classes
# get class distribution using numpy histogram function
self.class_dist = np.histogram(labels, bins=5, density=density, range=(0, 4))[0]
return self.class_dist
def plot_class_distributuion(self) -> np.array:
class_dist = self.get_class_distribution()
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
ax.bar(range(len(class_dist)), class_dist)
ax.set_xticks(range(len(class_dist)))
ax.set_xticklabels(land_cover_labels)
ax.set_ylabel('Number of Samples')
ax.set_title(f'Class Distribution: n_samples = {self.__len__()}')
fig.tight_layout()
plt.show()
return class_dist
Now, we’ll test out our NAIP_Dataset class using a subset of the original dataset.
subset_files = file_paths[:5] # select first 5 samples of full dataset for subset
subset_dataset = NAIP_Dataset(subset_files) # create dataset object
# since the __getitem__ method has been overridden, we can access samples in the
# dataset using the indexing operator [], similar to how we would index a list
X_temp, y_temp = subset_dataset[0] # get first sample in dataset
print_array_info(X_temp) # NOTE: because X and y are torch tensors, the output will vary sligtly from previous examples
print_array_info(y_temp)
visualize_raster(X_temp.numpy(), 'Subset sample')
visualize_target(y_temp.numpy(), 'Subset sample')
# check how many samples are in the dataset
print(f'Number of samples in dataset: {len(subset_dataset)}') # __len__ method has been overriden
# check class distribution
subset_dataset.plot_class_distributuion()
array shape: torch.Size([4, 224, 224])
array dtype: torch.float32
array range: tensor(0.) tensor(0.9695)
array shape: torch.Size([1, 224, 224])
array dtype: torch.float32
array range: tensor(1.) tensor(1.)

Number of samples in dataset: 5
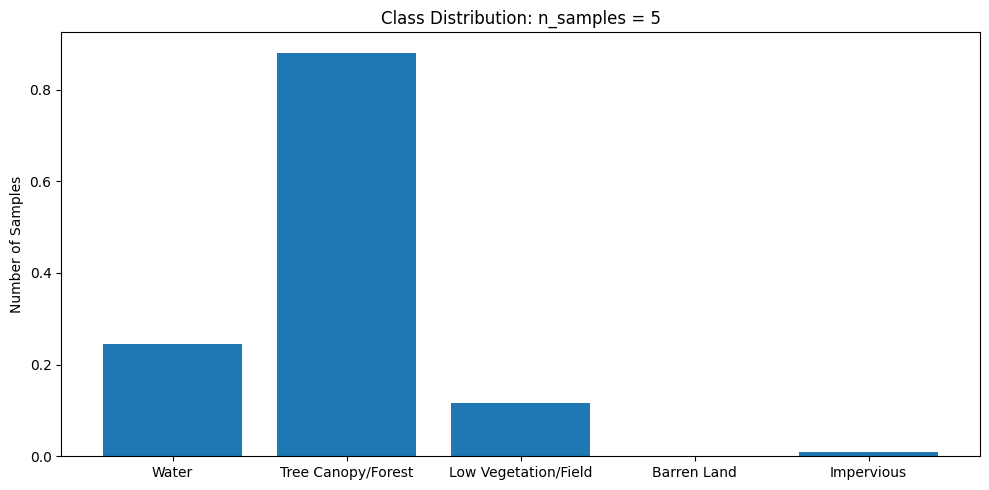
array([0.24408582, 0.88095404, 0.11646006, 0. , 0.00850008])
Image Transforms (Rotate and Flip)#
When training a deep learning model for image tasks we need to use as many training samples as possible. One widely-used method for artificially boosting the number of training samples seen by a model during training is data augmentation. Under data augmentation, we randomly apply a series of image transformations to each sample of training data before being passing it to the model during the training phase. Some examples of popular augmentation techniques include
Resizing
Cropping
Contrast adjustment
Color adjustment
Pixel jitter (shift the value of each pixel slightly)
Rotation
Flip (vertical and horizontal).
By augmenting data before training, we try to ensure that the model does not overfit on the dataset. When the model is overfit, the model captures features in the training data too well, leading to poor generalization on other data - significantly reducing the performance of the model on data it has not been trained on. Here, we will define a simple transform class that randomly rotates a sample by a multiple of 90 degrees as well as applying random flips.
from torchvision.transforms.functional import rotate, hflip, vflip
class RotateAndFlipTransforms:
def __init__(self) -> None:
self.angles = [90, 180, 270] # possible angles to rotate (0 and 360 are the same as the original)
self.p_rotate = 0.75 # probability of rotating
self.p_flip = 0.5 # probability of flipping
def __call__(self, X: torch.Tensor, y: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
# rotate with probability p_rotate
if random.random() < self.p_rotate:
angle = random.choice(self.angles) # if rotating, choose a random angle
X = rotate(X, angle)
y = rotate(y, angle)
# horizontal flip with probability p_flip
if random.random() < self.p_flip: # horizontal flip with probability p_flip
X = hflip(X)
y = hflip(y)
# vertical flip with probability p_flip
if random.random() < self.p_flip:
X = vflip(X)
y = vflip(y)
return X, y
transform = RotateAndFlipTransforms()
# testing the transform
X_temp_aug, y_temp_aug = transform(X_temp, y_temp)
# print array info
print_array_info(X_temp_aug)
print_array_info(y_temp_aug)
# visualize transformed data
# NOTE: should convert torch tensors to numpy arrays before visualizing
visualize_raster(X_temp.numpy(), title='Original raster')
visualize_raster(X_temp_aug.numpy(), title='Transformed raster')
visualize_target(y_temp.numpy(), title='Original target')
visualize_target(y_temp_aug.numpy(), title='Transformed target')
array shape: torch.Size([4, 224, 224])
array dtype: torch.float32
array range: tensor(0.) tensor(0.9695)
array shape: torch.Size([1, 224, 224])
array dtype: torch.float32
array range: tensor(1.) tensor(1.)


Putting it all together#
Now that we have the NAIP_Dataset class defined, we can put everything together and create three datasets: a test, validation, and train dataset. First, we need to create a RotateAndFlipTransforms object, then simply create three new NAIP_Dataset objects.
train_dataset = NAIP_Dataset(train_file_paths, transform=RotateAndFlipTransforms())
train_class_dist = train_dataset.get_class_distribution()
print('Class distribution for training set:', train_class_dist)
val_dataset = NAIP_Dataset(val_file_paths) # no need for transforms on validation/test sets
val_class_dist = val_dataset.get_class_distribution()
print('Class distribution for validation set:', val_class_dist)
test_dataset = NAIP_Dataset(test_file_paths)
test_class_dist = test_dataset.get_class_distribution()
print('Class distribution for test set:', test_class_dist)
Class distribution for training set: [0.23125458 0.61486403 0.38085044 0.00072105 0.02230991]
Class distribution for validation set: [2.23757079e-01 6.17434342e-01 3.87639769e-01 5.63034353e-04
2.06057753e-02]
Class distribution for test set: [2.23006232e-01 6.13281165e-01 3.91751534e-01 5.47302392e-04
2.14137672e-02]
Model building#
Now that we have a means of loading and visualizing data, we can start working on defining the model and it’s behavior. We will define the model and the loss function using the torch.nn.Module object-oriented API. This allows us to create a highly flexible and configurable model/loss.
Defining U-Net#
U-Net is a popular deep learning semantic segmentation architecture that uses convolutional layers to encode spatial features in an image to a lower dimensional feature space, then decodes the latent space to produce a final segmentation map. During inference, the outputs from each encoder layer are passed to the corresponding decoder layer in the decoder. U-Net was originally developed for binary segmentation of biomedical imagery, but is widely used in many disciplines that frequently deal with image-like data due to its simplicity and effectiveness.
# code is modified from https://github.com/milesial/Pytorch-UNet
# in order to comply with GPLv3, link to original code is provided above and
# GPL v3 license is included in the repository
""" Parts of the U-Net model """
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super(DoubleConv, self).__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False, padding_mode='reflect'),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False, padding_mode='reflect'),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super(Down, self).__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels): # remove bilinear option
super(Up, self).__init__()
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2], mode='reflect')
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, padding_mode='reflect')
def forward(self, x):
return self.conv(x)
""" Full assembly of the parts to form the complete network """
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, channels=[64, 128, 256, 512, 1024]):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.channels = channels
# need to use nn.ModuleList since encoder and decoder are lists of nn.Modules
self.encoder = nn.ModuleList([(DoubleConv(n_channels, channels[0]))])
for i in range(len(channels) - 1):
self.encoder.append(Down(channels[i], channels[i+1]))
self.decoder = nn.ModuleList([])
for i in range(len(channels) - 1, 0, -1):
self.decoder.append(Up(channels[i], channels[i-1]))
self.outc = (OutConv(channels[0], n_classes))
def forward(self, x):
encoder_layer_outputs = [] # need to store outputs from each layer in the encoder
for layer in self.encoder:
x = layer(x)
if len(encoder_layer_outputs) < len(self.encoder) - 1: # don't save output from last encoder layer
encoder_layer_outputs.append(x)
# pass output from each encoder layer to corresponding decoder layer
for layer in self.decoder:
x = layer(x, encoder_layer_outputs.pop()) # pass output from corresponding encoder layer
# final convolutional layer
return self.outc(x)
Testing our model#
Now that the model has been defined, it is a good idea to test it by creating a random input and passing it through the model. We do this to make sure the inputs and outputs match the dimensions of our dataset. In this case, our input is four-band imagery at 224x224 resolution, and our output should match the input resolution with 6 channels (one channel for each class).
Note that from now on, we will be primarily working with torch tensors instead of numpy arrays. A tensor is very similar to numpy array, but has special methods and attributes specifically designed for deep learning applications. For example, tensors can be placed in main memory (CPU), or on the GPU for increased performance during training and inference. Also note that Pytorch models expect inputs to have 4 dimensions. The first dimension refers to the batch size (i.e., we stack 16 tensors of shape (4, 224, 224) on top of each other to get a tensor with shape (16, 4, 224, 224)). The second dimension refers to the number of channels in the input data. Typically, when working with RGB imagery, only 3 input channels are needed. In our case, we are using 4-band data, so our model needs four input channels. The final two dimensions refer to the height and width of the input data, respectively.
model = UNet(n_channels=4, n_classes=5) # create mode
test_x = torch.randn(1, 4, 256, 256) # create a random input sample (dummy)
test_y = model(test_x) # feed the input sample to the model
print('Output shape:', test_y.shape) # print the output shape
assert test_y.shape == (1, 5, 256, 256) # make sure the output shape is correct
Output shape: torch.Size([1, 5, 256, 256])
Training the model#
Defining a loss function (focal loss)#
Before the model can be trained, we need to define a criterion to minimize. Typically, a cross-entropy loss function is used for semantic segmentation. However, because our dataset has a very extreme class imbalance, focal loss is a good approach to alleviate problems that arise when training on unbalanced datasets. From the paper:
“Our novel Focal Loss focuses training on a sparse set of hard examples and prevents the vast number of easy negatives from overwhelming the detector during training.”
More specifically, focal loss adds a modulating factor to the cross entropy loss, such that
\( \ell(p_t) = -(1-p_t)^{\gamma} \log{p_t} \),
where \( p_t = p \), the model’s estimated probability for the class label when the classification is correct, and \( p_t = 1 - p \) when the classification is incorrect. The presence of the modulating factor \( (1-p_t)^{\gamma} \) forces the model to focus on samples that are harder to classify. This is particularly handy in vision problems, where unbalanced datasets are common. Note that we can also include the class weight term \( \alpha \) into the such that \( \ell(p_t) = - \alpha (1-p_t)^{\gamma} \log{p_t} \) to further assist in training on unbalanced datasets.
# basic focal loss implementation from
# https://github.com/AdeelH/pytorch-multi-class-focal-loss/blob/master/focal_loss.py
from torch.nn import functional as F
class FocalLoss(nn.Module):
""" Focal Loss, as described in https://arxiv.org/abs/1708.02002.
It is essentially an enhancement to cross entropy loss and is
useful for classification tasks when there is a large class imbalance.
x is expected to contain raw, unnormalized scores for each class.
y is expected to contain class labels.
Shape:
- x: (batch_size, C) or (batch_size, C, d1, d2, ..., dK), K > 0.
- y: (batch_size,) or (batch_size, d1, d2, ..., dK), K > 0.
"""
def __init__(self, alpha=None, gamma=2., ignore_index=-100):
"""Constructor.
Args:
alpha (Tensor, optional): Weights for each class. Defaults to None.
gamma (float, optional): A constant, as described in the paper.
Defaults to 2.
ignore_index (int, optional): class label to ignore.
Defaults to -100.
"""
super().__init__()
if alpha is not None:
if not isinstance(alpha, torch.Tensor):
alpha = torch.tensor(alpha)
alpha = alpha.float()
self.alpha = alpha
self.gamma = gamma
self.ignore_index = ignore_index
self.nll_loss = nn.NLLLoss(weight=alpha, reduction='none', ignore_index=ignore_index)
def forward(self, x, y):
if x.ndim > 2:
# (N, C, d1, d2, ..., dK) --> (N * d1 * ... * dK, C)
c = x.shape[1]
x = x.permute(0, *range(2, x.ndim), 1).reshape(-1, c)
# (N, d1, d2, ..., dK) --> (N * d1 * ... * dK,)
y = y.view(-1)
unignored_mask = y != self.ignore_index
y = y[unignored_mask]
if len(y) == 0: return torch.tensor(0.)
x = x[unignored_mask]
# compute weighted cross entropy term: -alpha * log(pt)
# (alpha is already part of self.nll_loss)
# print(x.dtype)
log_p = F.log_softmax(x, dim=-1)
y = y.long() # https://discuss.pytorch.org/t/runtimeerror-expected-object-of-scalar-type-long-but-got-scalar-type-float-when-using-crossentropyloss/30542/2
ce = self.nll_loss(log_p, y)
# get true class column from each row
all_rows = torch.arange(len(x))
log_pt = log_p[all_rows, y]
# compute focal term: (1 - pt)^gamma
pt = log_pt.exp()
focal_term = (1 - pt)**self.gamma
# the full loss: -alpha * ((1 - pt)^gamma) * log(pt)
loss = focal_term * ce
loss = loss.mean() # only using mean reduction for simplicity
return loss
# quick test of focal loss
X_loss_test, y_loss_test = subset_dataset[0] # get first sample in dataset
# merge impervious classes
y_loss_test = merge_impervious_classes(y_loss_test)
# need to add batch dimension to input and target
X_loss_test = X_loss_test.unsqueeze(0)
y_loss_test = y_loss_test.unsqueeze(0)
test_loss_fn = FocalLoss() # create loss function object
y_hat_loss_test = model(X_loss_test) # run inference
test_loss = test_loss_fn(y_hat_loss_test, y_loss_test) # calculate loss
print('Loss: ', test_loss.item())
# Visualize inferred image. Will look bad at first, that's okay
y_raster = y_hat_loss_test.squeeze().detach() # convert target to numpy array
y_raster = y_raster.numpy()
y_raster = y_raster.argmax(axis=0)
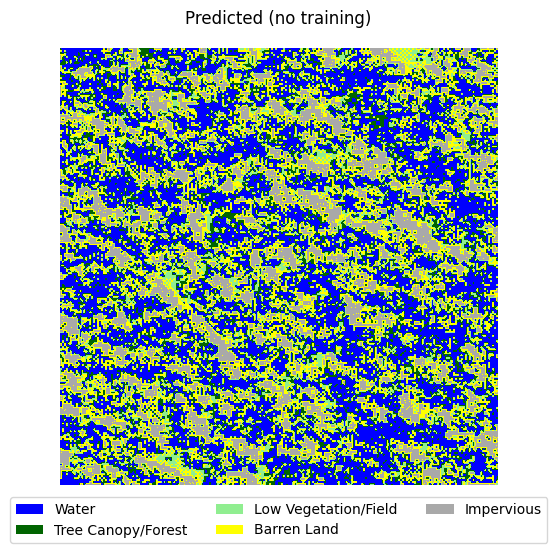
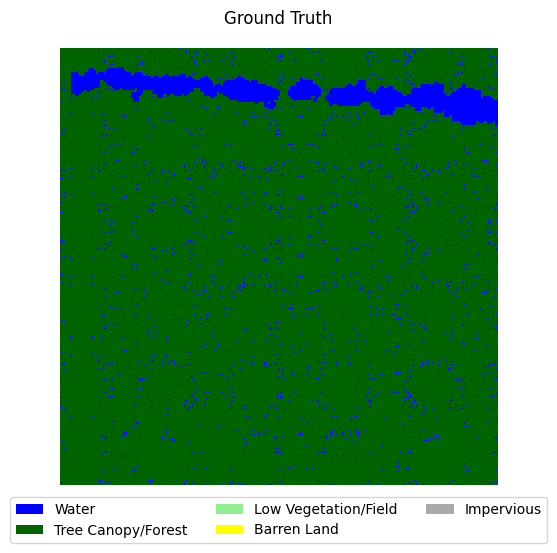
visualize_target(y_loss_test.squeeze().numpy(), title='Ground Truth')
visualize_target(y_raster, title='Predicted (no training)')
Loss: 1.1566414833068848
Altering weights for the loss function#
We want to emphasize the importance of classes that are hard to train in our loss function. We do this by passing weights for each class as the alpha parameter to the loss function. Classes with few examples will get a higher weight. We will generate those weights using the following code.
alpha = (1 - train_class_dist)**2 # increase exponent to increase weight of underrepresented classes
# make alpha mean = 1
alpha = alpha / alpha.mean()
print(alpha)
[0.96027595 0.24102336 0.62290542 1.62257376 1.55322151]
Hyperparameters, optimization, and GPU acceleration#
Now, we can set the hyperparameters, configure our optimizer, and set up GPU acceleration. For simplicity’s sake, we’ll use the Adam optimizer and a batch size of 8. In addition, we’ll use two learning rate schedulers to improve the stability of training - one will be a warmup scheduler that will reduce the learning rate during the first five epochs of training. After five epochs of training, the learning rate will be increased, upon which it will be reduced by a factor of 10 after every five epochs in which validation loss does not improve.
LEARNING_RATE = 0.0000001 # learning rate for optimizer - feel free to experiment
BATCH_SIZE = 16 # batch size to use
NUM_EPOCHS = 1000 # number of epochs to train for - will stop early if validation loss stops improving
FL_GAMMA = 2.0 # gamma parameter for focal loss
PATIENCE = 20 # patience for early stopping
WARMUP_EPOCHS = 10 # number of epochs for warmup
LR_PATIENCE = 5 # patience for learning rate scheduler
# optimizer and loss function setup
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
loss_fn = FocalLoss(gamma=FL_GAMMA, alpha=alpha)
warmup_scheduler = torch.optim.lr_scheduler.LambdaLR(
optimizer,
lambda x: 0.1*x if x < WARMUP_EPOCHS else 1, # lr reduced by a factor of 100 for first few epochs
verbose=True,
)
reduce_lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=LR_PATIENCE, verbose=True)
# use GPU if avaliable
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
print(f'Using device: {device}')
# enable CUDNN profiling (faster runtime)
torch.backends.cudnn.benchmark = True
Adjusting learning rate of group 0 to 0.0000e+00.
Using device: cuda
model = model.to(device) # move model to GPU if available
loss_fn = loss_fn.to(device) # move loss function to GPU if available
# visualize model architecture + number of trainable parameters
from torchinfo import summary
summary(model, input_size=(BATCH_SIZE, 4, 256, 256))
====================================================================================================
Layer (type:depth-idx) Output Shape Param #
====================================================================================================
UNet [16, 5, 256, 256] --
├─ModuleList: 1-1 -- --
│ └─DoubleConv: 2-1 [16, 64, 256, 256] --
│ │ └─Sequential: 3-1 [16, 64, 256, 256] 39,424
│ └─Down: 2-2 [16, 128, 128, 128] --
│ │ └─Sequential: 3-2 [16, 128, 128, 128] 221,696
│ └─Down: 2-3 [16, 256, 64, 64] --
│ │ └─Sequential: 3-3 [16, 256, 64, 64] 885,760
│ └─Down: 2-4 [16, 512, 32, 32] --
│ │ └─Sequential: 3-4 [16, 512, 32, 32] 3,540,992
│ └─Down: 2-5 [16, 1024, 16, 16] --
│ │ └─Sequential: 3-5 [16, 1024, 16, 16] 14,159,872
├─ModuleList: 1-2 -- --
│ └─Up: 2-6 [16, 512, 32, 32] --
│ │ └─ConvTranspose2d: 3-6 [16, 512, 32, 32] 2,097,664
│ │ └─DoubleConv: 3-7 [16, 512, 32, 32] 7,079,936
│ └─Up: 2-7 [16, 256, 64, 64] --
│ │ └─ConvTranspose2d: 3-8 [16, 256, 64, 64] 524,544
│ │ └─DoubleConv: 3-9 [16, 256, 64, 64] 1,770,496
│ └─Up: 2-8 [16, 128, 128, 128] --
│ │ └─ConvTranspose2d: 3-10 [16, 128, 128, 128] 131,200
│ │ └─DoubleConv: 3-11 [16, 128, 128, 128] 442,880
│ └─Up: 2-9 [16, 64, 256, 256] --
│ │ └─ConvTranspose2d: 3-12 [16, 64, 256, 256] 32,832
│ │ └─DoubleConv: 3-13 [16, 64, 256, 256] 110,848
├─OutConv: 1-3 [16, 5, 256, 256] --
│ └─Conv2d: 2-10 [16, 5, 256, 256] 325
====================================================================================================
Total params: 31,038,469
Trainable params: 31,038,469
Non-trainable params: 0
Total mult-adds (G): 874.76
====================================================================================================
Input size (MB): 16.78
Forward/backward pass size (MB): 9235.86
Params size (MB): 124.15
Estimated Total Size (MB): 9376.79
====================================================================================================
import warnings
warnings.filterwarnings('ignore') # ignore warnings for all cells below
DataLoader#
PyTorch uses the DataLoader class to select and batch samples during training. Because we are using a validation set as well as a training set,
from torch.utils.data import DataLoader
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, pin_memory=True, drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=True, pin_memory=True, drop_last=True)
from tqdm import tqdm # for progress bars
from IPython.display import clear_output # for clearing output in jupyter notebook
from sklearn.metrics import precision_score, recall_score # we will use these to keep track of model performance during training, more on this later
# save loss values for plotting
train_losses = []
val_losses = []
precision_scores = []
recall_scores = []
# only want to save the model with the best validation loss
best_epoch = 0
best_val_loss = float('inf') # set best validation loss to infinity to start
for epoch in range(NUM_EPOCHS):
# train step
epoch_train_loss = 0.0
model.train() # set model to train mode (enables autograd and dropout)
train_batch_losses = []
with tqdm(train_loader, unit="batch", desc=f'Epoch {epoch}/{NUM_EPOCHS} train step') as t_train: # create a progress bar for training
for X, y in t_train:
optimizer.zero_grad(set_to_none=True) # reset gradients to 0 (PyTorch does not do this automatically
# move data to GPU if available
X = X.to(device)
y = y.to(device)
y_hat = model(X)
loss = loss_fn(y_hat, y)
train_batch_losses.append(loss.item())
running_train_loss = sum(train_batch_losses) / len(train_batch_losses)
epoch_train_loss += (loss.item() * len(X)) # add total batch loss to epoch loss
t_train.set_postfix(loss=running_train_loss)
loss.backward() # backpropagate loss
optimizer.step() # update optimizer parameters (lr, momentum, etc.)
train_losses.append(running_train_loss) # calculate average loss for epoch and append to list
# validation step
model.eval() # set model to eval mode (disables autograd and dropout)
val_batch_losses = []
running_precision_scores = []
running_recall_scores = []
with tqdm(val_loader, unit="batch", desc=f'Epoch {epoch}/{NUM_EPOCHS} val step') as t_val: # create a progress bar for validation
for X, y in t_val:
# move data to GPU if available
X = X.to(device)
y = y.to(device)
y_hat = model(X)
loss = loss_fn(y_hat, y)
val_batch_losses.append(loss.item())
running_val_loss = sum(val_batch_losses) / len(val_batch_losses)
t_val.set_postfix(val_loss=running_val_loss)
# convert y and y_hat from torch tensors to numpy arrays and flatten
y_cpu = y.cpu().numpy().flatten()
y_hat_cpu = y_hat.argmax(axis=1).cpu().numpy().flatten() # argmax to convert from class confidence to class index
running_recall_scores.append(recall_score(y_cpu, y_hat_cpu, average='macro'))
running_precision_scores.append(precision_score(y_cpu, y_hat_cpu, average='macro'))
val_losses.append(running_val_loss) # calculate average loss for epoch and append to list
recall_scores.append(sum(running_recall_scores) / len(running_recall_scores))
precision_scores.append(sum(running_precision_scores) / len(running_precision_scores))
# update best validation loss and save model if new best is found
if val_losses[-1] < best_val_loss:
best_val_loss = val_losses[-1]
best_epoch = epoch
torch.save(model.state_dict(), './best_model.pth')
# plot training curves
clear_output(wait=True) # clear output before plotting
fig, ax1 = plt.subplots(figsize=(10, 5)) # create figure. will contain loss/accuracy curves
# loss curve (ax1 - left y axis)
fig.suptitle('Training Curves')
ax1.plot(train_losses, label='Train Loss')
ax1.plot(val_losses, label='Validation Loss')
ax1.set_xlabel('Epoch')
ax1.set_xlim(left=0)
ax1.set_ylabel('Focal Loss (mean)')
# determine left y axis range from min/max loss values
y_ax1_min = min(min(train_losses), min(val_losses)) # find lowest loss value across both curves
y_ax1_min = max(0, y_ax1_min - 0.1) # add some padding to the bottom of the plot. lower bound can't be less than 0
y_ax1_max = max(max(train_losses), max(val_losses)) + 0.1# find highest loss value across both curves, add some padding to the top of the plot
# set y axis limits
ax1.set_ylim(y_ax1_min, y_ax1_max)
# add veritcal line for best epoch
ax1.vlines(best_epoch, ymin=0, ymax=y_ax1_max, label=f'best epoch={best_epoch}\nval loss={best_val_loss:.3f}', linestyles='dashed', colors='black')
# add legend
ax1.legend(loc='upper left') # put next to upper left corner of plot
# create right y axis for precision/recall curves
ax2 = ax1.twinx()
# plot precision/recall curves
ax2.plot(precision_scores, label=f'Precision/UA\n{precision_scores[best_epoch]:.3f} @ {best_epoch}', color='red')
ax2.plot(recall_scores, label=f'Recall/PA\n{recall_scores[best_epoch]:.3f} @ {best_epoch}', color='green')
ax2.set_ylabel('Precision/Recall (mean)')
ax2.set_ylim(0, 1) # set y axis limits to 0-1
plt.legend(loc='upper right') # put legend in upper right corner of plot
plt.show() # show plot
# show example prediction
y_hat_plot = y_hat[0].detach().cpu().numpy() # convert target to numpy array\
y_hat_plot = y_hat_plot.argmax(axis=0)
visualize_raster(X[0].cpu().numpy(), title='Input Raster')
visualize_target(y[0].cpu().numpy(), title='Ground Truth')
visualize_target(y_hat_plot, title=f'Inference at epoch {epoch}')
# early stopping
if epoch - best_epoch > PATIENCE:
print(f'Validation loss has not improved for {PATIENCE} epochs. Stopping early at epoch {epoch}')
break
# finally, update schedulers
if epoch < WARMUP_EPOCHS: # if still in warmup phase
warmup_scheduler.step()
else:
reduce_lr_scheduler.step(val_losses[-1])
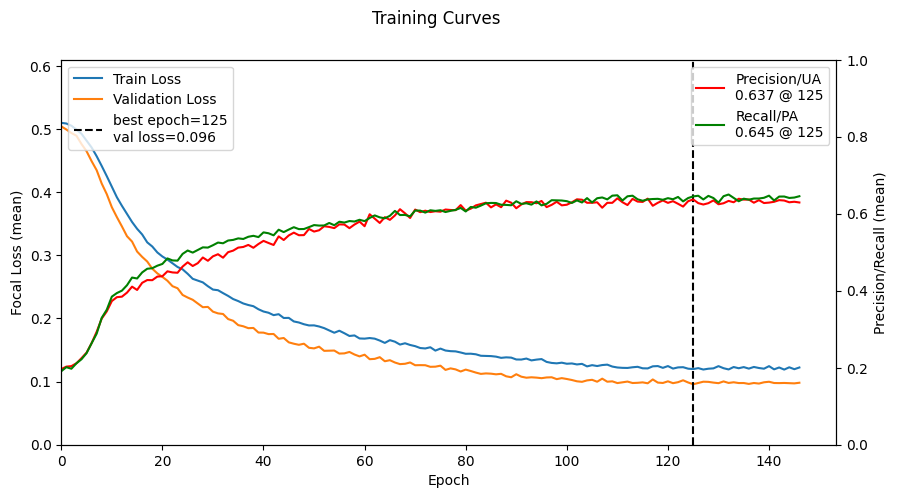


Validation loss has not improved for 20 epochs. Stopping early at epoch 146
Evaluation#
Now that the model has been trained, the final (and most important) step is to determine the model’s performance by performing inference on an annotated holdout “test” set.
Metrics#
The simplest way to construct metrics on a per-class basis is to first count the number of true positives, false positives, true negatives, and false negatives by comparing the ground truth data and the models predictions. For enhanced accuracy, we can do this on a per-class basis.
True Positives (\( TP \)): positive prediction is correct - (\( \hat{y} = 1; y = 1 \))
False Positives/type I error (\( FP \)): positive prediction is incorrect - (\( \hat{y} = 1; y = 0 \))
True Negatives (\( TN \)): negative prediction is correct - (\( \hat{y} = 0; y = 0 \))
False Negative/type II error (\( FN \)): negative prediction is incorrect - (\( \hat{y} = 0; y = 1 \))
Next, using these values, we can construct accuracy metrics:
Accuracy: ratio of correct predictions to the total number of predictions (\( ACC = \frac{TP + TN}{TP + FP + TN + FN} \))
User’s accuracy/precision: ratio of total number of true positives to true positives and false positives (\( UA = \frac{TP}{TP + FP} \))
Producer’s accuracy/recall: ratio of total number of true positives to true positives and false negatives (\( PA = \frac{TP}{TP + FN} \))
Intersection over Union (IoU): ratio of true positives to true positives, false positives, and false negatives (\(IoU = \frac{TP}{TP + FP + FN} \)) - we won’t use this one, but it
F1-score: harmonic mean of user’s accuracy and producer’s accuracy - commonly referred to as precision and recall, respectively (\(F1 = \frac{2 \cdot UA \cdot PA}{UA + PA}\))
Typically, a good model will have similar results for both producer’s and user’s accuracy - large differences between PA and UA typically indicates the model is biased towards certain classes. IoU is a good metric for determining how well the model can discriminate between foreground regions and background regions, though we will not implement it here.
Thankfully, sklearn has a classification_report function that can generate these precision, recall, and f1 scores on a per-class basis.
from sklearn.metrics import classification_report
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, pin_memory=False)
ys = np.array([])
y_hats = np.array([])
# load the best model
model.load_state_dict(torch.load('best_model.pth'))
# look at class distribution of test set
test_class_dist = test_dataset.get_class_distribution()
print(test_class_dist)
# find nuber of samples in each class
test_class_samples = np.round(test_class_dist * len(test_dataset) * (224**2)).astype(int)
print(test_class_samples)
for X, y in tqdm(test_loader, unit="batch", desc='Test step'):
# move data to GPU if available
X = X.to(device)
y = y.to(device)
y_hat = model(X)
y_hat = y_hat.argmax(axis=1) # convert from one-hot to class index
# cppend batch results to numpy arrays
ys = np.append(ys, y.detach().cpu().numpy().flatten())
y_hats = np.append(y_hats, y_hat.detach().cpu().numpy().flatten())
cr = classification_report(ys, y_hats, labels=range(0,5), target_names=land_cover_labels)
print(cr)
[2.23006232e-01 6.13281165e-01 3.91751534e-01 5.47302392e-04
2.14137672e-02]
[13785539 37911099 24216839 33833 1323731]
Test step: 100%|██████████| 77/77 [00:32<00:00, 2.35batch/s]
precision recall f1-score support
Water 0.94 0.95 0.94 11028431
Tree Canopy/Forest 0.96 0.84 0.90 30328879
Low Vegetation/Field 0.78 0.93 0.85 19373471
Barren Land 0.00 0.00 0.00 27066
Imperivious 0.54 0.56 0.55 1058985
accuracy 0.88 61816832
macro avg 0.64 0.66 0.65 61816832
weighted avg 0.89 0.88 0.88 61816832
Overall, the results are mixed. The model excels at classifying water, tree canopy, and low vegetation (to a lesser extent), but is poor at classifying barren land and impervious classes. One reason for the poor performance on both the barren land and impervious classes is the lack of support for those classes in the training and testing dataset. Recall earlier that this dataset is extremely unbalanced. In order to boost the performance the barren land and impervious classes, we would need to source more samples that contain those classes.
Confusion matrix#
To get a better idea of how the model is classifying based on the input data, we can generate a confusion matrix. Confusion matrices show the difference between the ground truth data and the model’s inferences on a class-by-class basis.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay, classification_report
cm = confusion_matrix(ys, y_hats, normalize='true', labels=range(0,5))
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=land_cover_labels)
disp.plot(xticks_rotation='vertical')
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x255b962fee0>
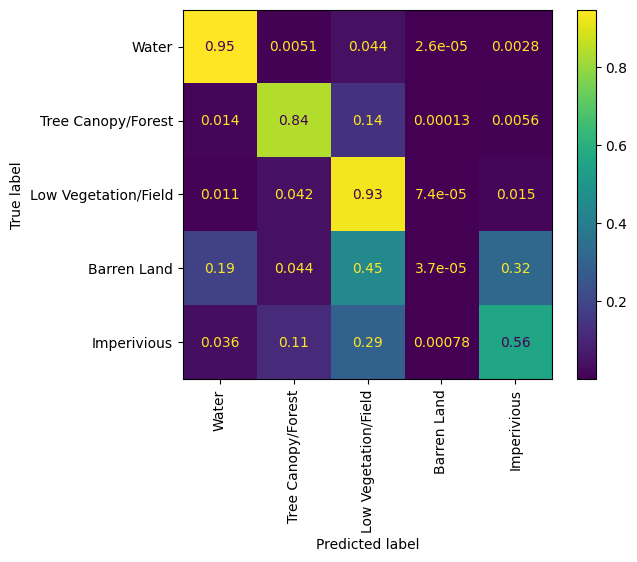
The model obviously struggles with classifying impervious and barren land classes, most likely due to the lack of samples in the dataset.
Visual analysis#
Finally, let’s look at some example predictions on the hold-out data to make sure our model’s inferences look accurate, since metrics only give us part of the story.
# final visual anaylysis
# create subplots for each raster, ground truth, and prediction
fig, ax = plt.subplots(BATCH_SIZE, 4, figsize=(15, 60))
ax[0][0].set_title('RGB Raster')
ax[0][1].set_title('CIR Raster')
ax[0][2].set_title('Ground Truth')
ax[0][3].set_title('Prediction')
for i in range(BATCH_SIZE):
# use sample from final batch of test loader
raster = X[i].cpu().numpy() # convert to numpy array
ground_truth = y[i].cpu().numpy()
pred = y_hat[i].cpu().numpy()
rgb_raster = raster[:3] # get RGB channels
cir_raster = raster[[3, 0, 1]] # get CIR channels
# transpose to (H, W, C) for matplotlib
rgb_raster = rgb_raster.transpose(1, 2, 0)
cir_raster = cir_raster.transpose(1, 2, 0)
# squeeze to remove extra dimension
ground_truth = ground_truth.squeeze()
pred = pred.squeeze()
# plot
ax[i][0].imshow(rgb_raster)
ax[i][1].imshow(cir_raster)
ax[i][2].imshow(ground_truth, cmap=land_cover_cmap, vmin=0, vmax=5)
ax[i][3].imshow(pred, cmap=land_cover_cmap, vmin=0, vmax=5)
# remove axis ticks and labels
ax[i][0].axis('off')
ax[i][1].axis('off')
ax[i][2].axis('off')
ax[i][3].axis('off')
# add land cover legend
fig.legend(handles=land_cover_legend, loc='upper center', bbox_to_anchor=(0.5, 1.01), ncol=5)
fig.tight_layout()

Overall, the inferences are not terrible. While the model’s predictions are not perfect (it particularly struggles with barren land), the ground truth samples are not 100% accurate either.
All in all, the model did not perform exceptionally well, but it can classify water, forest, and low vegetation fairly accurately. There are some tweaks we can make to improve the performance of our model.
Use a higher quality (preferably hand-annotated) dataset.
Selectively sample to reduce class imbalance
Use a deeper/more powerful model (such as DeepLabv3+)